xv6
实现 trace
- 实验指导
- 实现一个跟踪 syscall 的 syscall
- 阅读这篇 lec06 syscall 了解系统调用的整个过程 , 然后参考其中一个 syscall 代码即可 :
在 syscall 入口判断进程 trace_mask
void
syscall(void)
{
.......
//trace
if ( (1 << num) & p->trace_mask ) {
printf("%d: syscall %s -> %d\n", p->pid, syscall_name[num], p->trapframe->a0);
}
.........
}
trace 系统调用,设置 trace_mask
uint64
sys_trace(void) {
int mask;
if (argint(0, &mask) < 0) {
return -1;
}
struct proc* p = myproc();
p->trace_mask = mask;
return 0;
}
给进程页表添加内核页表映射
- 实验指导
- 阅读这篇 lec04 page table 了解 xv6 的地址空间构成 , 页 entry 结构
- 为什么要添加内核页表映射 ? 因为当前的 xv6 实现中 , 在内核态要访问用户进程指针是通过软件模拟的形式访问的 , 效率没有用 mmu 访问高
- 如何实现 ? 类似 linux , 将整个地址空间划分成两大部分 , 上面部分是内核空间 , 下面部分是用户空间 (xv6 里用户进程最多只有 100 多 MB)
- 在创建进程的时候 , 除了页目录的第一项之外 , 其他都映射为内核页表 , 第一项比较特殊,因为里面还包含了内核态的硬件寄存器,这一项得生成用户独立的页表,然后把硬件寄存器映射过去
- 然后在 copyin 的时候直接 dereference 用户指针即可 , 不用再 walk 页表
pagetable_t
proc_kpagetable()
{
pagetable_t pagetable = uvmcreate();
int i;
for (i=1;i<512;i++) {
pagetable[i] = kernel_pagetable[i];
}
ukvmmap(pagetable, UART0, UART0, PGSIZE, PTE_R | PTE_W);
ukvmmap(pagetable, VIRTIO0, VIRTIO0, PGSIZE, PTE_R | PTE_W);
ukvmmap(pagetable, CLINT, CLINT, 0x10000, PTE_R | PTE_W);
ukvmmap(pagetable, PLIC, PLIC, 0x400000, PTE_R | PTE_W);
return pagetable;
}
free 的时候也要小心,别把 kernel 的entry 和物理地址给 free 掉了 , kernel 地址的 PTE_V 为 0
void
proc_freekpagetable(pagetable_t level1)
{
pte_t pte = level1[0];
pagetable_t level2 = (pagetable_t) PTE2PA(pte);
for (int i=0;i<512;i++) {
pte_t p = level2[i];
if (p & PTE_V) {
uint64 level3 = PTE2PA(p);
kfree((void*)level3);
level2[i]=0;
}
}
kfree((void*)level2);
kfree((void *) level1);
}
在调度的时候切换到进程的 k 页表 , 而不是全局的 k 页表
void
scheduler(void)
{
..........
w_satp(MAKE_SATP(p->kpagetable));
sfence_vma();
............
}
问题记录:
把 kernel 的 pagetable 也 free 掉了,导致 kerneltrap
init: starting sh
$ usertests
usertests starting
scause 0x000000000000000d
sepc=0x0000000080001d88 stval=0x000000021fdcc000
panic: kerneltrap
QEMU: Terminated
kernel.asm
80001d84: 01248f63 beq s1,s2,80001da2 <proc_freekpagetable+0x40>
pte_t p = level2[i];
80001d88: 6088 ld a0,0(s1)
if (p & PTE_V) {
80001d8a: 00157793 andi a5,a0,1
一个 helper function , 可以打印执行栈:
原理, 取当前的 frame pointer, 然后-8得到 return address , 打印出来 , 然后可以配合 elf 文件获得函数名
void backtrace() {
uint64 fp = r_fp();
uint64 down = PGROUNDDOWN(fp);
while (fp>down) {
printptr(* (uint64*)(fp-8));
consputc('\n');
fp = *(uint64*)(fp-16);
}
}
实现用户态 trap alarm (类似信号)
- 实验指导
- 阅读lec05 和 lec06
- 整个流程是: 用户态通过sigalarm 设置定时触发的 handler
- 当时钟中断时发现已经到时间, 则把上下文切换到 handler , 并返回用户态执行
- 当 handler 执行到末尾的时候, 执行 sigreturn 系统调用, 进入内核态,并切换回进程的原上下文, 然后返回用户态
- 这里需要模拟 syscall 的上下文切换 swtch.S , 在时钟中断中把进程的上下文保存起来,然后切换到 handler 的上下文
- xv6 把从用户态进入 interrupt , exception , syscall 的代码都写在 usertrap 里了
- 上面三者任何一个触发, 都会跳到 trapoline 的代码执行 , 然后把当前的寄存器值保存在 trapframe
uint64 sys_sigalarm(void) {
struct proc *p = myproc();
int n;
uint64 handler;
if (argint(0,&n) <0) {
return -1;
}
if (argaddr (1,&handler)<0) {
return -1;
}
p->alarm_ticks = n;
p->alarm_ticked = 0;
p->alarm_handler = handler;
return 0;
}
uint64 sys_sigreturn(void) {
struct proc *p = myproc();
memmove(p->trapframe,&(p->etpfm),sizeof(struct trapframe));
p->alarm_ticked = 0;
// is this atomic ?
p->alarming = 0;
return 0;
}
void usertrap() {
......
// give up the CPU if this is a timer interrupt.
if(which_dev == 2) {
if (p->alarm_ticks>0) {
p->alarm_ticked++;
if (p->alarming==0 && p->alarm_ticked >= p->alarm_ticks) {
// is this atomic ?
p->alarming = 1;
memmove(&(p->etpfm),p->trapframe,sizeof(struct trapframe));
p->trapframe->epc = p->alarm_handler;
}
}
yield();
}
......
}
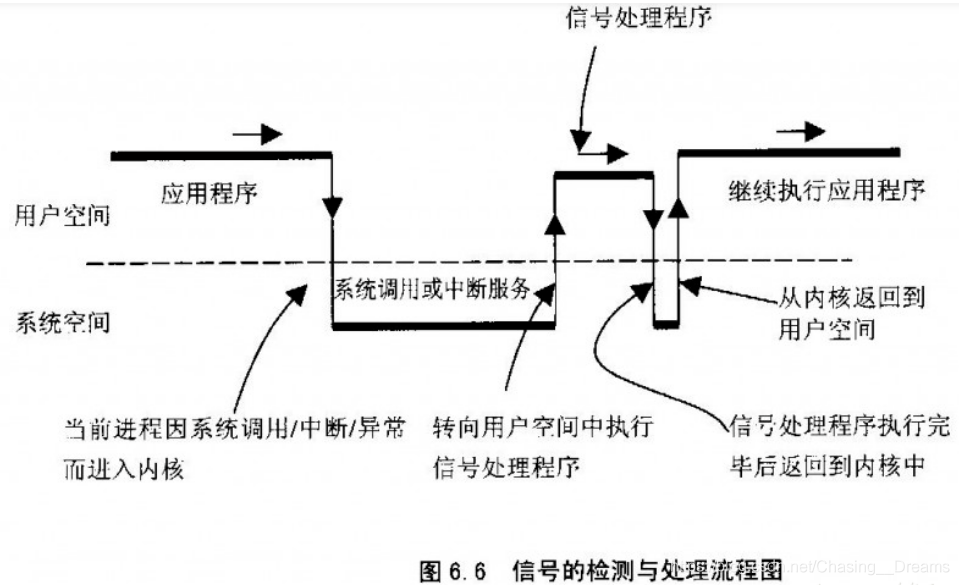
之前看 linux 信号存的一张流程图 , 帮助理解
lazy allocation
- 实验指导
- 阅读 lec08
- 实现延迟分配的理由 ? 大部分时候, 进程要求的内存可能并不会被立即用到
- 比如申请一个 10000 大小的数组 , 一开始可能只存了一两个元素, 这时候如果先分配完整的空间是一种浪费
- 如何实现 ? 先不映射物理地址, 而是等到访问到的时候再映射
- 如果某个进程的地址没有相应的映射 (PTE_U 为 0) , 那么 MMU 访问的时候就会触发一个 page fault
- 我们可以在 page fault handler 中为这个地址添加映射, 然后返回用户态正常运行
void usertrap(void){
....
} else if (r_scause() == 13 || r_scause() == 15) {
uint64 f_addr = r_stval();
char* mem = kalloc();
if (mem==0) {
p->killed = 1;
} else {
memset(mem,0,PGSIZE);
if (mappages(p->pagetable,f_addr,PGSIZE,(uint64)mem,PTE_W|PTE_R|PTE_X|PTE_U) <0) {
p->killed = 1;
kfree(mem);
}
//kpagetable map needed ? oh right , there is no kpagetable !
}
f_addr = PGROUNDDOWN(f_addr);
} else {
....
}
uint64 pgfault_alloc(uint64 va) {
// uint64 va = r_stval();
struct proc* p = myproc();
uint64 ustack = p->trapframe->sp;
char* mem;
// for understand
int top_addr = p->sz - 1;
if (va < PGROUNDUP(ustack)) {
return 0;
} else if (va > top_addr) {
return 0;
} else {
va = PGROUNDDOWN(va);
mem = kalloc();
if (mem==0) {
return 0;
} else {
memset(mem,0,PGSIZE);
if (mappages(p->pagetable,va,PGSIZE,(uint64)mem,PTE_W|PTE_R|PTE_X|PTE_U) <0) {
kfree(mem);
return 0;
}
return (uint64)mem;
//kpagetable map needed ? oh right , there is no kpagetable in the lab !
//xxxxxxxxxx
}
}
}
实现 fork cow
- 实验指导
- 阅读 lec08
- 和 lazy 的理由差不多 , 延迟到访问的时候再分配内存 ,同样也是使用 page fault 实现
- 当一个被多个进程使用的地址被访问时 , 会触发 pg fault 然后 alloc 一个新页面, 把旧页面数据复制过来 , 再映射到新页面上
- 同时需要增加引用计数做内存回收 , 只有一个地址的计数为 0 才可以安全 free
kmem 结构里增加 refcnt 做计数
struct {
struct spinlock lock;
struct run *freelist;
int refcnt[PHYSTOP/PGSIZE];
} kmem;
void usertrap(){
........
if(r_scause() == 13 || r_scause() == 15){
if (duppage(p->pagetable,r_stval()) <0 ) {
p->killed = 1;
}
} else if(r_scau
........
}
int
uvmcopy(pagetable_t old, pagetable_t new, uint64 sz)
{
.............
// if page is writable , clear the PTE_W bit ( to trigger pg fault)
if (*pte & PTE_W) {
*pte &= ~ PTE_W;
*pte |= PTE_COW;
// printf("ucmcopy:COW set");
}
flags = PTE_FLAGS(*pte);
incr(pa,1);
if(mappages(new, i, PGSIZE, (uint64)pa, flags) != 0){
printf("ucmopy:mappage error");
// kfree(mem);
*pte &= ~(PTE_COW | PTE_W);
*pte |= pte_w_cow_before;
...........
}
// copy the va page data to a new pa ,
// and point ppn(physical page num) to new pa
int duppage(pagetable_t pagetable,uint64 va) {
pte_t* pte;
// uint64 pa;
//va = PGROUNDDOWN(va);
if (va >=MAXVA) {
printf("duppage: >=MAXVA");
return -1;
}
pte = walk(pagetable,va,0);
//user operate on a invalid page , throw error
if (pte==0) {
printf("duppage: pte=0");
return -1;
}
if ((*pte & PTE_U) == 0) {
printf("duppage: PTE_U ==0");
return -1;
}
if ((*pte & PTE_V) == 0) {
printf("duppage: PTE_V==0");
return -1;
}
// no need to duppage
if ((*pte & PTE_COW) ==0) {
// printf("duppage: COW==0");
return -2;
}
uint64 oldpa = PTE2PA(*pte);
uint64 newpa = (uint64)kalloc();
if (newpa==0) {
return -1;
}
memmove((void*)newpa,(void*)oldpa,PGSIZE);
uint64 flags = PTE_FLAGS(*pte);
flags = (flags & ~PTE_COW) | PTE_W;
*pte = PA2PTE(newpa) | flags;
// printf("duppage in");
kfree((void*)oldpa);
return 0;
}
实现用户态线程 (协程)
- 实验指导
- 阅读 Lec11 Thread switching
- 这里要实现的其实是协程 , 即协作式调度(主动让出控制权)的两个执行栈 , 称为 coroutine
- 用户态是可以访问和修改部分寄存器的 , 只需要在切换到另一个协程前保存好上下文,切换到另一个协程的上下文即可,参考 swtch.S 的汇编代码
- 这里其实不需要保存那么多寄存器, 但是因为懒就直接复制过来吧
优化锁粒度
- 实验指导
- 阅读 Lec10 Multiprocessors and locking
- 优化 memlist 和 bcache 锁粒度
- 内存链表是个大锁,在多核的情况下会发生争用,优化方案是每个 cpu 都有自己的内存链表
- 那这样岂不是有点浪费? 如果某个 cpu 没跑任何程序 . 所以还有个 steal 的策略, 如果不够用就从其他 cpu 偷点内存过来
- go 中也有类似的设计, work steal , 还有 P 上的 mcache
- bcache 全称 block cache , 是磁盘 block 在内存中的缓存 , 由于 bcache 链表大小固定且有淘汰策略, 读取新的 block 的时候需要锁整个 bcache,产生争用
- 优化方案, 把 bcache 做分区 , 按 hash 分成多个区 , 减小锁粒度
- 那淘汰的时候本分区没有可以淘汰的怎么办? 遍历其他分区找 , 也是 steal 的策略
- 以什么作为分区key , block id
- 可能会导致倾斜
实现大文件支持和符号链接
- 实验指导
- 阅读 Lec14 File systems , Lec15 Crash recovery , Lec16 File system performance and fast crash recovery
大文件支持:
- xv6 的 inode 共有13个 block , 12 个 direct block , 一个 indirect block , 12 + 1* block size / entry size
- 增加一个三级 indirect block , 11个 direct block ,一个一级 Block , 一个三级 block
符号链接:
- 符号链接也是一个 inode , 当文件对待, 不同的是inode data 部分不存 block num , 而是存目标路径字符串
mmap
todo
network driver
todo
gdb 调试 xv6 的一些技巧
todo
有用的图示
todo
资料汇总
todo